captcha-1
La verdad detrás de los nuevos noCaptchas de Google
Los nuevos noCaptchas de Google han sido recibidos con alegría, pero su funcionamiento interno recoge varias sorpresas.
4 diciembre, 2014 18:06Noticias relacionadas
- El nuevo doodle de Google celebra el aniversario del Apolo 11 y la llegada a la Luna
- Google te pagará tres veces más si encuentras fallos en sus productos
- Cuando veas porno vigila la puerta... y la privacidad: Google y Facebook saben lo que ves
- La muerte de los "likes": Instagram empieza a ocultarlos
Según el consultor Egor Homakov no deberíamos creernos tan al pie de la letra las explicaciones de Google sobre noCaptcha. Después de investigar un poco su funcionamiento, ha llegado a la conclusión de que su funcionamiento es mas simple de lo que parece, está abierto a abusos y peor aún, básicamente crea dos tipos de usuario en Internet.
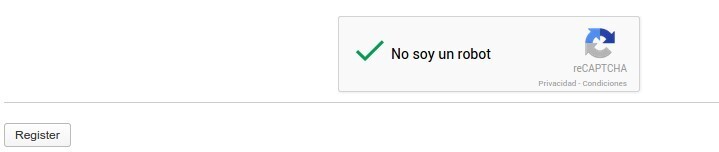
Ayer os presentamos la evolución de los captchas, llamados noCaptcha. Google los anunció de manera triunfal como una muestra de su trabajo en aprendizaje automático, asegurando que el sistema que había desarrollado era capaz de analizar nuestro comportamiento para averiguar si realmente somos una persona de verdad o un bot. Gracias a este trabajo en segundo plano, los usuarios solo tenemos que marcar una casilla para demostrar que no somos un bot. Suena muy bonito y adelantado a su tiempo, pero de Google ya nos hemos acostumbrado a creernos cualquier cosa futurista que nos presenta.
Captchas con truco
nocaptcha-1
Homakov en cambio asegura que no todo es tan bonito. Si probamos el nuevo captcha, por ejemplo en la página de registro de WordPress, veremos que funciona perfectamente y seguramente solo necesitaremos marcar la casilla. Sin embargo, si abrimos la misma página en una ventana de incógnito, no nos bastará con eso y tendremos que rellenar el captcha de texto habitual. Eso es porque en realidad lo que hace noCaptcha es repasar nuestro historial, como por ejemplo si ya hemos resuelto captchas en el pasado. Homakov lo dice con una palabra: cookies.

nocaptcha-2
La clave está en el valor de la variable “g-recaptcha-response”, que es la que define si somos merecedores de un captcha de texto o no. En definitiva, ahora mismo en Internet hay dos grupos de usuarios, los que Google considera “buenos” y los que considera “sospechosos”, aunque es posible pasar de uno a otro. Por supuesto, los bots que no consigan pasar el primer filtro pueden usar software OCR para reconocer los caracteres de los captchas de texto, igual que antes. De hecho, Homakov llega a decir que con noCaptcha la seguridad ha empeorado.
Y es que noCaptcha puede saltarse solamente con tener generado “g-recaptcha-response”, es decir, con haber acertado la suficiente cantidad de captchas; el problema es que ese valor puede “robarse” fácilmente, por ejemplo incluyendo el noCaptcha de manera invisible en nuestra página para que un visitante “bueno” genere respuestas automáticamente sin saberlo. Por no mencionar que es fácil encontrar trabajadores dispuestos a pasar 1000 captchas por un dólar, provenientes sobre todo de países asiáticos y del tercer mundo.
Al final, la conclusión que tenemos que sacar es que es inevitable que los spammers y otros usuarios malintencionados sean capaces de saltarse los impedimentos que les ponen empresas como Google. Al menos el nuevo noCaptcha es mas sencillo para la mayoría de los usuarios, pero si no sirve para dejar fuera a indeseados, es poco probable que dure demasiado.
Fuente | Egor Homakov




