robot exhibicion londres 4
Machine Learning y Deep Learning, ¿qué diferencia hay?
Machine Learning y Deep Learning son dos conceptos diferentes, aunque obviamente unidos. Dado que muchas veces se confunden, te explicamos la diferencia.
3 junio, 2017 13:03Noticias relacionadas
- Estos robots microscópicos son tan diminutos que se mueven a base de vibraciones
- Tomar curvas peligrosas con la moto será menos peligroso con esta IA avisándonos
- El cofundador de Siri se une al equipo de Sherpa, el asistente inteligente español
- Intel crea un "cerebro" digital con 8 millones de neuronas, imitando a los nuestros
Entre tanto ruido mediático, es fácil perderse y no saber qué es Machine Learning, es Deep Learning o no saber cuál es la diferencia entre ambos.
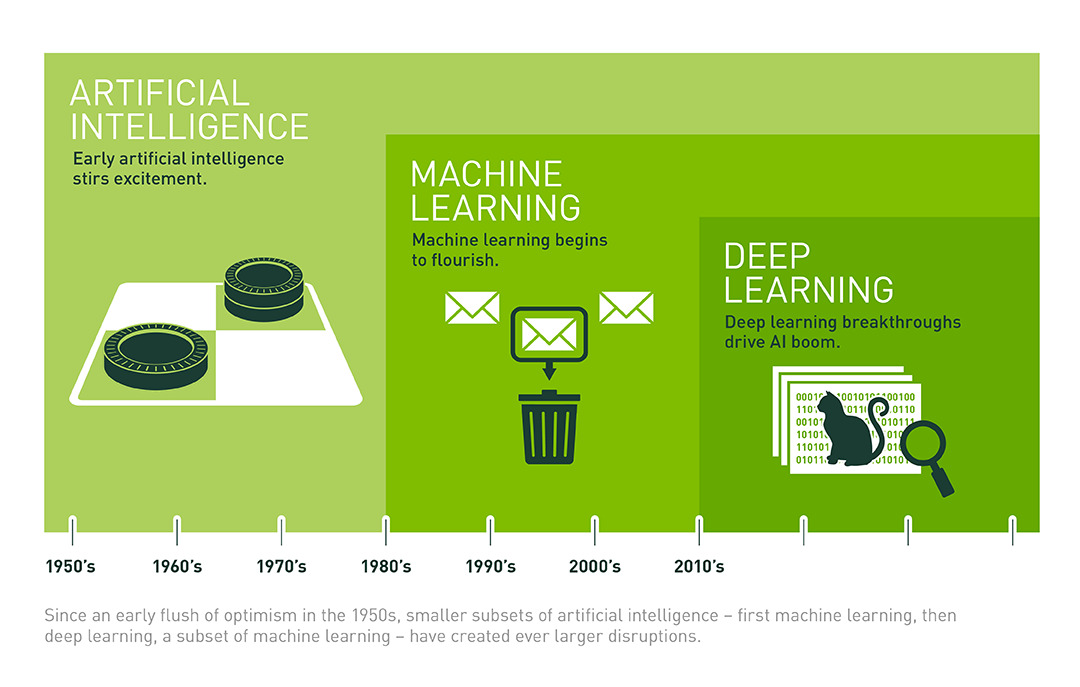
Llevamos ya mucho tiempo oyendo cosas sobre el Maching Learning y el Deep Learning, pero, ¿sabemos realmente lo que es? Por supuesto, hay que destacar que esto no es algo de 2017 ni de 2016. Ni siquiera se trata de algo novedoso del s. XXI, sino más bien en la década de los años 50’s (solo que en aquel entonces las máquinas no eran tan potentes y por lo tanto no daban para seguir desarrollando más profundamente esta tecnología).
Deep_Learning_Icons_R5_PNG.jpg
Lo primero que hay que tener claro es que no es viable programar a una IA, pues si no, no se diferenciaría en nada a la computación tradicional. La propia Inteligencia Artificial debe aprender por sí misma (ya veremos cómo).
Machine Learning
El Machine Learning (ML; Aprendizaje automático en español) es, per se, una Inteligencia Artificial. Es justamente el conjunto de algoritmos que aprender por sí mismo. Es, básicamente, quien (o mejor dicho, lo que) se encarga de ‘programar’. Dentro del Machine Learning hay dos métodos.
Supervised Learning
El primero es lo que se conoce como Aprendizaje dirigido en español. ‘Aprendizaje supervisado’ sería una mala traducción, pues desde luego no hay nadie supervisando lo que una máquina aprende o no, sino más bien dirigiendo.
Vamos a explicarlo por medio del diagrama de abajo (para que sea más sencillo). Como vemos, la IA recibe un estímulo o ejemplo (lo que se conoce como parseo de datos). El algoritmo de Aprendizaje automático (y más concretamente de Aprendizaje supervisado) lo procesa y extrae un modelo. Con este modelo, cada vez que se introduce un nuevo dato la máquina es capaz de dar una respuesta.

supervised-learning ia
Un caso práctico sería, por ejemplo, el sistema de filtrado de SPAM de Google: el usuario ayuda a identificar a Gmail cuáles son los correos electrónicos que contienen SPAM. Llegado a un determinado punto, la IA ya ha procesado tantos datos que es capaz de extraer un modelo para poder predecir con alta probabilidad de éxito cuáles de los correos que vayan entrando sean correos basura para que ni siquiera sean mostrados.
Otro ejemplo más ‘visual’ es el proceso de aprendizaje por el que pasaría una IA que se dedica a reconocer qué fotografías incluyen caras (por ejemplo, para sacar una foto cada vez que se reconozca a una persona): se introducen fotografías con o sin caras para que la máquina sea capaz de diferenciarlas. Por supuesto cada uno de los elementos que introducimos tiene que estar etiquetado (es decir, decirle a la IA si tiene una cara o no).
Unsupervised Learning
Ahora, efectivamente, toca el caso del Aprendizaje no dirigido. También se le conoce como el Deep Learning (DL; Aprendizaje profundo). En este otro método de Machine Learning no se introducen ejemplos, sino que es el propio algoritmo de la máquina el que debe sacar patrones o anomalías para crear un modelo.

sup_vs_unsup_learning_diagram
Pongamos ahora un caso práctico: tenemos una base de datos donde están los datos de mil personas junto con su nombre, su edad, su estado físico y sus hábitos alimenticios. Si queremos saber cuáles son los hábitos alimenticios menos saludables, tendremos que ir comparando cada uno de ellos con el estado de salud física de la persona hasta que encontremos el patrón.
En este caso, más que patrón, anomalía, que sería la comida no saludable. Por supuesto este ejemplo no es verídico (es muy básico y los resultados podrían ser no siempre válidos), pues necesitaríamos también otros datos, como por ejemplo el tipo de genética de la persona o la cantidad y el tipo de ejercicio que realizan.

Machine-Learning
En concreto el aprendizaje profundo imita el comportamiento de un sistema nervioso. En el Supervised Learning, las redes neuronales usadas se comportan de forma monolítica. Es decir, todas las neuronas artificiales se comportan de igual manera entre sí. Esto es, pueden cumplir todas las mismas funciones.
En un sistema nervioso esto no ocurre así. Cada red neuronal tiene una función específica. Esto es, cada neurona (realmente cada capa) es experta en una sola característica. Pues en el Deep Learning se imita precisamente ese comportamiento.