deepweb
La Internet Profunda: El lado oculto de la Red
Noticias relacionadas
- El nuevo doodle de Google celebra el aniversario del Apolo 11 y la llegada a la Luna
- La muerte de los "likes": Instagram empieza a ocultarlos
- DAZN, el Netflix de los deportes, emitirá los Juegos Olímpicos, Roland Garros, la Fórmula E y más, pero sube el precio
- En Japón ya tienen "consignas para redes sociales", que te bloquean la cuenta el tiempo que quieras desconectar
Y es que entre tanta información era necesario ya hace años una guía, algo que nos ayudara a buscar y encontrar aquello que necesitamos. Así fue como nacieron los buscadores como Yahoo o Google que a medida que han ido pasando los años han ido perfeccionando sus métodos para indexar y guardar en su base de datos todas aquellas páginas que pueden. Porque existen limitaciones y páginas a las que no pueden rastrear.
¿Cómo existe la internet profunda?
El trabajo “sucio” de los buscadores los hacen sus arañas, un particular nombre para un software que se dedica a recorrer la red en busca de páginas y de la información que contienen. Seria absurdo y tremendamente lento que fuera en el momento de la búsqueda el buscador se dedicara a rebuscar en internet aquello que buscamos. Por eso manda a sus arañas en busca de información que luego clasifica por diferentes temáticas en una gigantesca base de datos. De esta forma cuando nosotros buscamos algo nos puede devolver resultados en cuestión de segundos, millones de ellos.
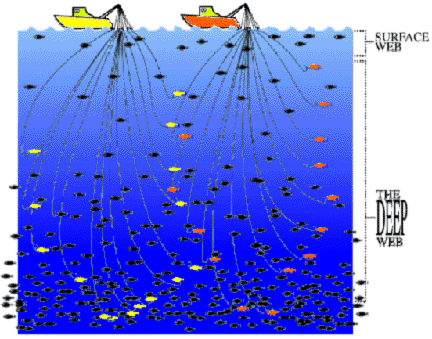
internet profundo
Pero no todo es accesible, ni todo cumple los mínimos para que una araña de cualquier buscador pueda acceder a la información que una página contiene. De hecho,
Un concepto que se entiende mucho mejor con una comparación que hacen en un artículo, los buscadores pueden compararse con grandes redes de arrastre. Una gran cantidad de cosas pueden arrastrarse con la red en la parte más superficial , pero hay una gran cantidad de información que queda en la profundidad y que se pierde. Y es por este mismo motivo que la internet profunda es de una magnitud enorme. Según un estudio de la Universidad de Berkeley se estima que actualmente la internet profunda debería tener un tamaño aproximado de unos 91.000 Terabytes, esto es unas 550 veces más grande que el internet convencional.

internet profunda 03
Con unas cifras así uno se pregunta qué cantidad de cosas nos estaremos perdiendo, y cuantas respuestas a nuestras preguntas probablemente se encuentren dentro de las profundidades no indexadas. Un fenómeno fascinante y que arroja datos muy interesantes como que
Esto derribaría uno de los mitos más frecuentes de la internet profunda, que muchos imaginan como refugio de delincuentes, pederastas y donde circula material de muy dudosa legalidad. Evidentemente hay de todo pero no todo es tan oscuro y paralelo. Tan sólo hay que investigar un poco para poder acceder a ciertas partes de esa internet escondida, como los enlaces .onion (con la red Tor). Así que si buscas más respuestas que las convencionales y crees que pueden hallarse en las profundidades de la red ¿te adentrarás en la internet profunda?
Via Wikipedia